
hadoop(一)
Hadoop是一个分布式系统基础架构,现在通常指一个分布式hadoop生态圈,用于海量数据存储与分析计算。
Hadoop 3.x组成
- common
- hdfs
- yarn
- mapreduce
NameNode DateNode Secondary node
- NameNode(nn):存储元数据
- DataNode: 存储文件块数据以及校验和
- Secondary NameNode node(2nn) : 每个一段时间对NameNode进行元数据备份。
yarn
- resource manager
- Node Manager
- applicationMaster
- container 容器
说明: 1.有多个客户端 2. 集群可以运行多个ApplicationMaster 3. 每个NodeManager可以有多个Container(默认1g-8g内存)
hadoop安装
- ip配置与主机名称
hadoop /etc/sysconfig/network-script/ens33 /etc/hostname /etc/hosts
VM
windows - 配置文件/etc/profile
自动配置模块。 scp -r 拉取/推送两种方式。
[!NOTE]
- xsync 集群分发
- ssh免密登录
集群配置
- core-site.xml namenode地址、hadoop数据存储目录
- hdfs-site.xml nnweb地址、2nnweb地址
- yarn-site.xml mapreduce协议、ResourceManager地址、环境变量继承(高版本解决)
- mapred-site.xml mapreduce在Yarn运行
- workers
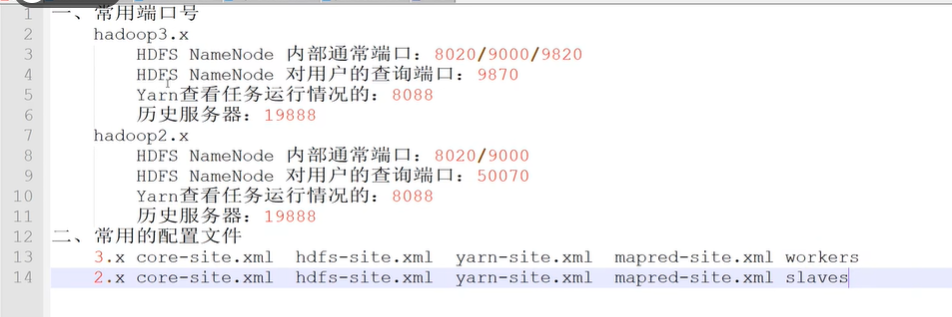
hdfs:9870 yarn:8088 jobhistory (内部 10020 web 19888)
hadoop初始化
hdfs namenode -format
故障恢复
a. 服务停掉,先yarn在dfs.
b. 删除data与logs 避免版本不一致,把每个集群的都删除。
c. 格式化
d. 启动- 历史服务器
a. 配置mapred-site.xml
b. shutdown yarn 每个节点都stop,同时启动是在resource manager中进行。
c. start yarn
d. bin/mapred —daemon start historyserver - 启动顺序
a. hdfs
b. yarn
c. historyserver
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 秋叶半金!